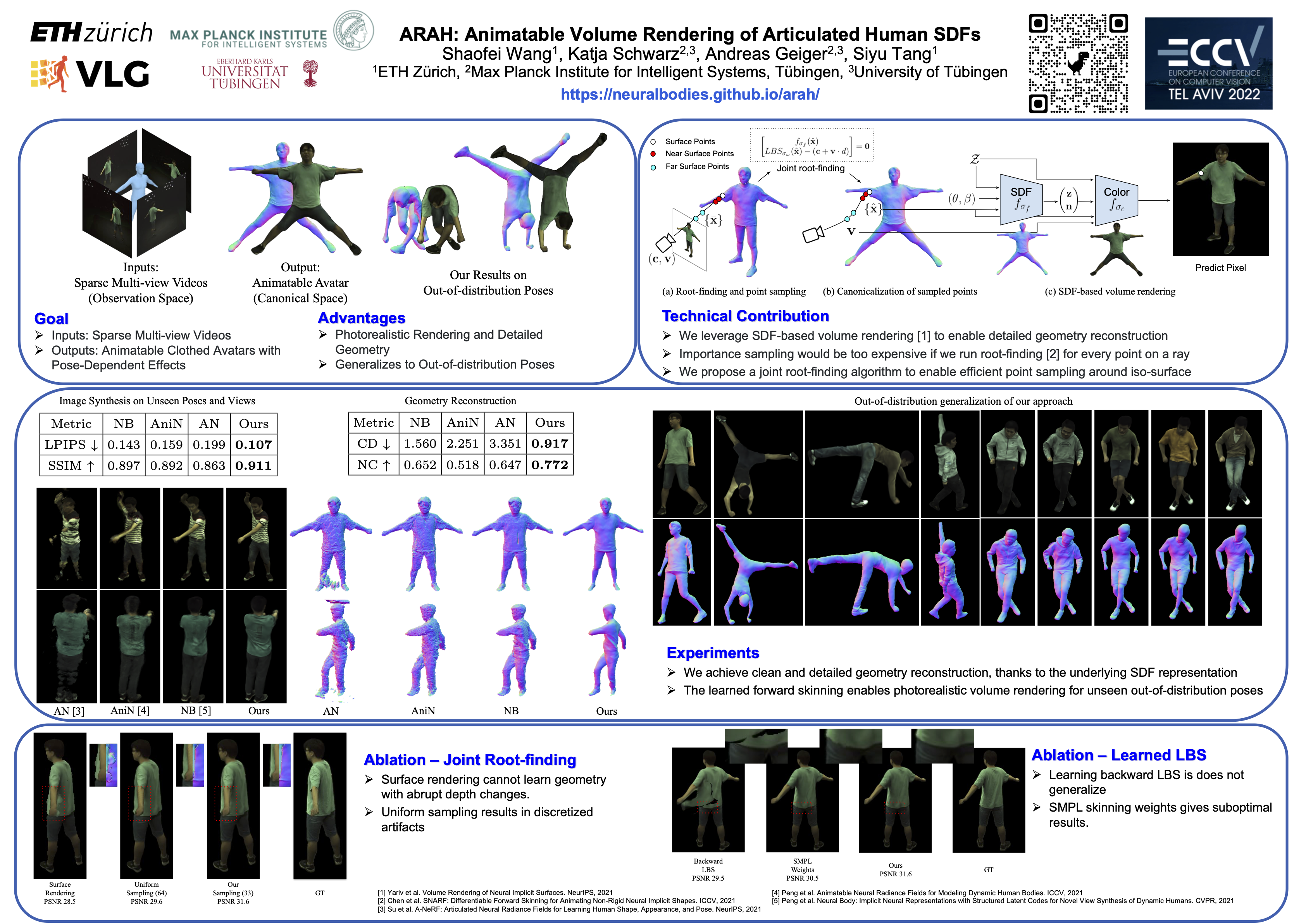
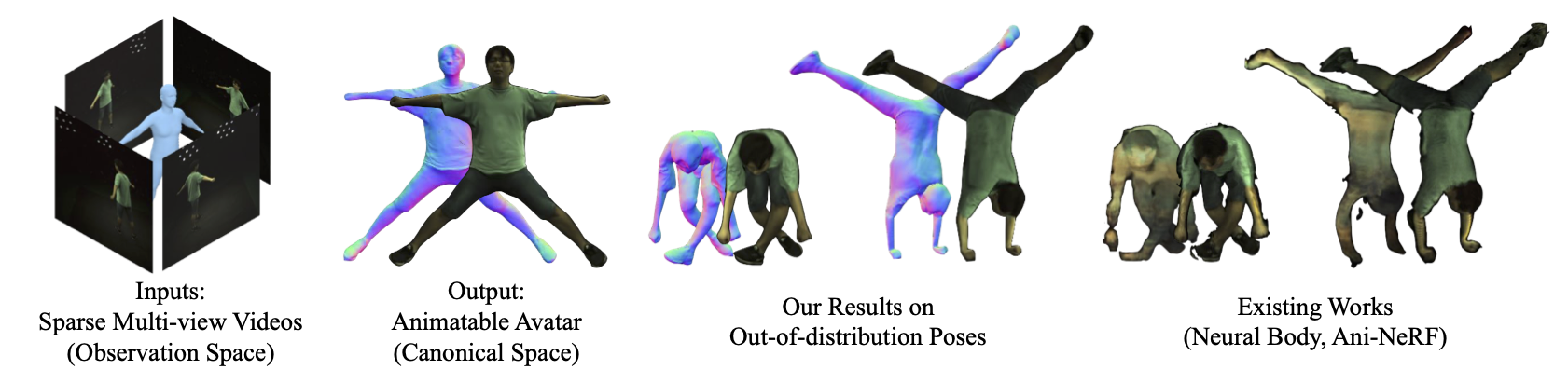
ARAH combines articulated human SDFs with a novel joint root-finding algorithm to solve the problem of simultaneously searching ray-surface intersections and their correspondences in canonical space for rendering. This enables efficient and accurate sampling for volume rendering of clothed human avatars, which have both detailed pose-dependent geometry and appearance, while generalizing well to out-of-distribution test poses.
Overview
Our model consists of a forward linear blend skinning (LBS) network, a canonical SDF network, and a canonical color network. When rendering a specific pixel of the image in observation space, we first find the intersection of the corresponding camera ray and the observation-space SDF iso-surface. Since we model a canonical SDF and a forward LBS, we propose a novel joint root-finding algorithm that can simultaneously search for the ray-surface intersection and the canonical correspondence of the intersection point (Section 3.3 of the paper). Such a formulation does not condition the networks on observations in observation space. Consequently, it can generalize to unseen poses. Once the ray-surface intersection is found, we sample near/far surface points on the camera ray and find their canonical correspondences via forward LBS root-finding. The canonicalized points are used for volume rendering to compose the final RGB value at the pixel. The model is trained end-to-end using the photometric loss and regularization losses.